Scalable Storage in the Cloud
🔎Overview
- Key-Value based object storage with unlimited storage, unlimited objects up to 5 TB for the internet
S3is an Object level storage (not a Block level storage) and cannot be used to host OS or dynamic websites (but can work with Javascript SDK)- provides durability by redundantly storing objects on multiple facilities within a region
- regularly verifies the integrity of data using checksums and provides auto healing capability
- integrates with
CloudTrail,CloudWatchandSNSfor event notifications - bucket names have to be globally unique
- data model is a flat structure with no hierarchies or folders
- Logical hierarchy can be inferred using the keyname prefix e.g. Folder1/Object1
- Objects stored in S3 have the URL format:
https://s3-[region].amazonaws.com/[bucketname]/[filename] - If you host a static website in S3 the URL format:
http://[bucketname].s3-website-[region].amazonaws.com S3is object based. Objects consist of the following:- Key - unique, developer-assigned key
- Value - this is the data which consists of sequence of bytes.
- VersionID - used for versioning
- Metadata - data about data e.g. Content-Type, Author, CreateDate etc.
- Subresources - bucket specific configuration like Bucket policies and ACLs
🪣Buckets
- allows retrieval of 1000 objects and provides pagination support and is NOT suited for list or prefix queries with large number of objects
- with a single
PUToperations, 5GB size object can be uploaded - use Multipart upload to upload large objects up to 5 TB and is recommended for object size of over 100 MB for fault tolerant uploads
- support Range HTTP Header to retrieve partial objects for fault tolerant downloads where the network connectivity is poor
- Pre-Signed URLs can also be used/shared for uploading/downloading objects for limited time without requiring AWS security credentials
- allows deletion of a single object or multiple objects (max 1000) in a single call
- Multipart Uploads allows:
- parallel uploads with improved throughput and bandwidth utilization
- fault tolerance and quick recovery from network issues
- ability to pause and resume uploads
- begin an upload before the final object size is known
Consistency
- provide read-after-write consistency for
PUTSof new objects and eventual consistency for overwritePUTSandDELETES(i.e., updating or deleting existing objects) - for new objects, synchronously stores data across multiple facilities before returning success
- updates to a single key are atomic
Versioning
- You can version your files in Amazon
S3. It is enabled at the bucket level. - allows preserve, retrieve, and restore every version of every object
- Same key overwrite will increment the version.
- It is best practice to version your buckets to protect against unintended deletes (ability to restore a version) and easy roll back to previous version.
- Any file that is not versioned prior to enabling versioning will have version null
- Suspending versioning does not delete the previous versions
- protects individual files but does NOT protect from bucket deletion
S3 Static Website Hosting
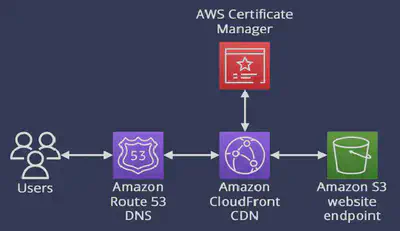
- Bucket name must match the
domain(e.g., example.com) - Website files (HTML, CSS, JS) are uploaded to the bucket
- Key Configurations
- Enable static website hosting in bucket properties
- Set index document (e.g.,
index.html) - Optionally set error document (e.g.,
404.html) - Make objects public via bucket policy or ACLs
CloudFront CDN. You would enable Origin Access Control (OAC) which would grant CloudFront permission to access private S3 objects.CORS
CORS- Cross Origin Resource Sharing is a typical concern when using resources from anotherdomain.
When using
S3buckets to store static resources(images, js, css) for a WebApp, since S3 buckets are not in the same domain as the WebApp, the browser will block loading the resources.The requests won’t be fulfilled unless the other origin allows for the requests, using
CORSHeaders (Access-Control-Allow-Origin)To configure your bucket to allow cross-origin requests, you create a
CORSconfiguration, which is an XML document with rules that identify the origins that you will allow to access your bucket, the operations (HTTP methods) that will support for each origin, and other operation-specific information.You can allow for a specific
originor for*(all origins):<CORSConfiguration> <CORSRule> <AllowedOrigin>*</AllowedOrigin> <AllowedMethod>GET</AllowedMethod> <MaxAgeSeconds>3000</MaxAgeSeconds> <AllowedHeader>Authorization</AllowedHeader> </CORSRule> </CORSConfiguration>
Replication
- Objects can be replicated between two buckets.
- Must enable versioning in source and destination Buckets
- Buckets can be in different accounts
- Copying is asynchronous
- Must give proper
IAMpermissions toS3 - Replication could be
- Cross Region Replication (CRR) - Use cases: compliance, lower latency access, replication across accounts
- Same Region Replication (SRR) - Use cases: log aggregation, live replication between production and test accounts
- After activating, only new objects are replicated (not retroactive)
- For
DELETEoperations:- If you delete without a version ID, it adds a
deletemarker, not replicated - If you delete with a version ID, it deletes in the source, not replicated
- So in short
DELETEoperations are NOT replicated.
- If you delete without a version ID, it adds a
- There is no chaining of replication i.e. if bucket 1 has replication into bucket 2, which has replication into bucket 3 then objects created in bucket 1 are not replicated to bucket 3
🛡️Security
IAM policies – grant users within their own AWS account permission to access S3 resources.
- Example: S3 IAM Access
Allows the user to perform
s3:ListBucketon the root of the specified bucket(<YOUR_BUCKET_NAME_HERE>) in a specified AWS region(<YOUR_REGION>) originating from a specific IP (<YOUR_IP>/32)Grants
s3:GetObjectands3:PutObjectpermissions within a user-specific folder. Same IP and region restrictions apply.Allows
s3:PutObjectonly if the object is encrypted usingSSE-S3(AES256).{ "Version": "2012-10-17", "Statement": [ { "Condition": { "StringEquals": { "aws:RequestedRegion": "<YOUR_REGION>" }, "IpAddress": { "aws:SourceIp": "<YOUR_IP>/32" } }, "Action": [ "s3:ListBucket" ], "Resource": "arn:aws:s3:::<YOUR_BUCKET_NAME_HERE>", "Effect": "Allow" }, { "Condition": { "StringEquals": { "aws:RequestedRegion": "<YOUR_REGION>" }, "IpAddress": { "aws:SourceIp": "<YOUR_IP>/32" } }, "Action": [ "s3:PutObject", "s3:GetObject" ], "Resource": "arn:aws:s3:::<YOUR_BUCKET_NAME_HERE>/Engineering/${aws:username}/*", "Effect": "Allow" }, { "Condition": { "StringEquals": { "s3:x-amz-server-side-encryption": "AES256" }, "IpAddress": { "aws:SourceIp": "<YOUR_IP>/32" } }, "Action": [ "s3:PutObject" ], "Resource": "arn:aws:s3:::<YOUR_BUCKET_NAME_HERE>/Engineering/encrypted/*", "Effect": "Allow" } ] }
Bucket and Object ACL – grant other AWS accounts (not specific users) access to S3 resources
Bucket policies – allows to add or deny permissions across some or all of the objects within a single bucket
Example - Anonymous Read Access
{ "Version": "2012-10-17", "Id": "Policy1589785443274", "Statement": [ { "Sid": "Stmt1589785361449", "Effect": "Allow", "Principal": "*", "Action": "s3:GetObject", "Resource": "arn:aws:s3:::<bucketname>/*" } ] }Example - Origin Access Control via
CloudFront
{ "Version": "2012-10-17", "Statement": [ { "Sid": "AllowCloudFrontServicePrincipal", "Effect": "Allow", "Principal": { "Service": "cloudfront.amazonaws.com" }, "Action": "s3:GetObject", "Resource": "arn:aws:s3:::<BUCKET_NAME>/*", "Condition": { "StringEquals": { "AWS:SourceArn": "arn:aws:cloudfront::<ACCOUNT_ID>:distribution/<CLOUDFRONT_DISTRIBUTION>" } } } ] }- Example - MultiFactorAuth
{ "Version": "2012-10-17", "Statement": [ { "Sid": "EnforceMFAForObjectDelete", "Effect": "Deny", "Principal": "*", "Action": "s3:DeleteObject", "Resource": "arn:aws:s3:::<BUCKET_NAME>/*", "Condition": { "Null": { "aws:MultiFactorAuthAge": "true" } } } ] }
📂Storage
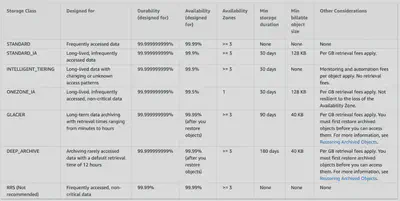
Standard
- Default storage class
- 99.999999999% durability & 99.99% availability
- Low latency and high throughput performance
- designed to sustain the loss of data in a two facilities
Standard IA
- optimized for long-lived and less frequently accessed data
- designed to sustain the loss of data in a two facilities
- 99.999999999% durability & 99.9% availability
- suitable for objects greater than 128 KB kept for at least 30 days
One Zone-IA
- High durability (99.999999999%) in a single AZ; data lost when AZ is destroyed
- 99.5% Availability
- Use Cases: Storing secondary backup copies of on-premises data, or data you can recreate
Glacier Instant Retrieval
- Millisecond retrieval, great for data accessed once a quarter
- Minimum storage duration of 90 days
Glacier Flexible Retrieval
- suitable for archiving data where data access is infrequent and retrieval time of several (3-5) hours is acceptable.
- 99.999999999% durability
- allows Lifecycle Management policies
- transition to move objects to different storage classes and Glacier
- expiration to remove objects
- Minimum storage duration of 90 days
- 3 retrieval options:
- Expedited (1 to 5 minutes)
- Standard (3 to 5 hours)
- Bulk (5 to 12 hours)
Glacier Deep Archive
- For long term storage – cheaper than Glacier
- 2 retrival options:
- Standard (12 hours)
- Bulk (48 hours)
- Minimum storage duration of 180 days
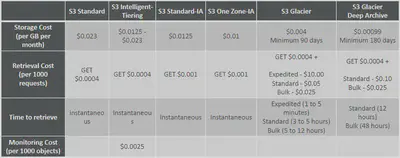
Comparison of Storage Tiers
Storage Lifecycle
You can transition objects between storage classes either manually or via Lifecycle policies.
Here’s a diagram to show the transition paths possible:
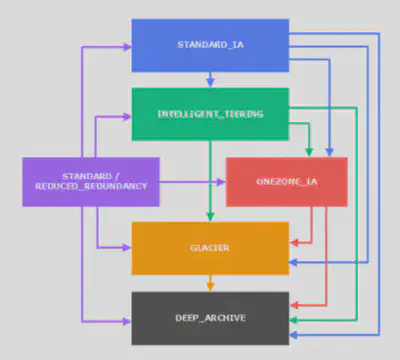
Transition actions: It defines when objects are transitioned to another storage class. Like for eg:
- Move objects to
Standard IAclass 60 days after creation - Move to
Glacierfor archiving after 6 months - Expiration actions: configure objects to expire (delete) after some time
- Access log files can be set to delete after a 365 days
- Can be used to delete old versions of files (if versioning is enabled)
- Can be used to delete incomplete multi-part uploads
- Move objects to
Rules can be created for a certain prefix (ex - s3://mybucket/mp3/*)
Rules can be created for certain objects tags (ex - Department: Finance)
🔐Encryption
Supports HTTPS (
SSL/TLS) encryption in TRANSIT🚌S3 Bucket Policies – Force SSL:
To force SSL, create an S3 bucket policy with a DENY on the condition
aws:SecureTransport = false{ "Id": "ExamplePolicy", "Version": "2012-10-17", "Statement": [ { "Sid": "AllowSSLRequestsOnly", "Action": "s3:*", "Effect": "Deny", "Resource": [ "arn:aws:s3:::DOC-EXAMPLE-BUCKET", "arn:aws:s3:::DOC-EXAMPLE-BUCKET/*" ], "Condition": { "Bool": { "aws:SecureTransport": "false" } }, "Principal": "*" } ] }
Note: Using an ALLOW on
aws:SecureTransport = truewould allow anonymousGetObjectif using SSL
- Data encryption at REST💤.
There are a several options:
SSE-S3- AES256 bit encryption, S3 managed keysSSE-KMS- KMS managed keys, customer has access to envelope key and that is a key which actually encrypts your data’s encryption key, audit trail available viaCloudTrailSSE-KMS DSSE- Enables dual-layer server-side encryption with AWS KMS (SSE-KMS DSSE).SSE-C: customer managed encryption keys - keys are not stored inKMS. CloudHSM could be usedClient SideEncryption - key not stored inKMSGlacier: all data is AES-256 encrypted, key under AWS control
- You configure a bucket to use default encryption via the S3
console,CLI, orAPI. Ensures encryption even if clients forgets to include encryption headers. - AWS automatically encrypts every object uploaded to the bucket unless the
PUTrequest explicitly specifies a different encryption method. - You can choose between:
SSE-S3(AES256)SSE-KMS(aws:kms)SSE-KMS DSSE(aws:kms:dsse)
If the client wants the file be encrypted(or override default encryption) at upload time they can specify the
x-amz-server-side-encryptionheader parameter in the request header.These are the possible values for the
x-amz-server-side-encryptionheader:AES256–> which tells S3 to use S3-managed keys,aws:kmsORaws:kms:dsse–> which tells S3 to use KMS–managed keys.
The old way to enable default encryption in a bucket was to use a bucket policy and refuse any HTTP command without the proper headers:
Security Policy for enforcing encryption via
SSE-S3:{ "Version": "2012-10-17", "Id": "PutObjPolicy", "Statement": [ { "Sid": "DenyIncorrectEncryptionHeader", "Effect": "Deny", "Principal": "*", "Action": "s3:PutObject", "Resource": "arn:aws:s3:::<bucket_name>/*", "Condition": { "StringNotEquals": { "s3:x-amz-server-side-encryption": "AES256" } } }, { "Sid": "DenyUnEncryptedObjectUploads", "Effect": "Deny", "Principal": "*", "Action": "s3:PutObject", "Resource": "arn:aws:s3:::<bucket_name>/*", "Condition": { "Null": { "s3:x-amz-server-side-encryption": true } } } ] }Security Policy for enforcing encryption via
SSE-KMS:It gets more interesting with the
SSE-KMScase. Here we need to deny all requests that use the wrong encryption type, i.e.x-amz-server-side-encryption = AWS256or an incorrect KMS key, i.e. the value ofx-amz-server-side-encryption-aws-kms-key-id. A rule for that looks like this (You need to replace $BucketName, $Region, $Accountid and $KeyId):{ "Version": "2012-10-17", "Statement": [ { "Effect": "Deny", "Principal": "*", "Action": "s3:PutObject", "Resource": "arn:aws:s3:::$BucketName/*", "Condition": { "StringNotEqualsIfExists": { "s3:x-amz-server-side-encryption": "aws:kms" }, "Null": { "s3:x-amz-server-side-encryption": "false" } } }, { "Effect": "Deny", "Principal": "*", "Action": "s3:PutObject", "Resource": "arn:aws:s3:::$BucketName/*", "Condition": { "StringNotEqualsIfExists": { "s3:x-amz-server-side-encryption-aws-kms-key-id": "arn:aws:kms:$Region:$AccountId:key/$KeyId" } } } ] }
- Bucket Policies are evaluated before default encryption.
- This means if your bucket policy denies uploads without encryption headers, the request will be blocked even before default encryption can apply.
- So if your policy requires encryption headers, you must ensure clients explicitly include them, or relax the policy to allow default encryption to do its job.
- If you’re using default encryption, your bucket policy should not require encryption headers. Instead, use a defensive policy to enforce HTTPS but does not block default encryption.
{
"Effect": "Deny",
"Principal": "*",
"Action": "s3:*",
"Resource": ["arn:aws:s3:::your-bucket-name", "arn:aws:s3:::your-bucket-name/*"],
"Condition": {
"Bool": {
"aws:SecureTransport": "false"
}
}
}
👣Access Logs
S3 Server Access Logging provides detailed records of the requests made to your S3 bucket. It’s an essential feature for security auditing, access monitoring, and understanding your S3 traffic patterns.
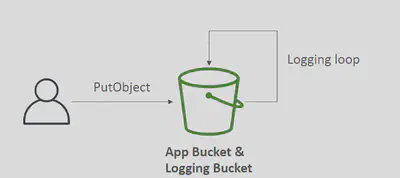
- Any request made to S3, from any account, authorized or denied, will be logged into another destination S3 bucket
- The destination bucket must be in the same
AWS RegionandAWS accountas the source bucket. - That data can be analyzed using data analysis tools, or Amazon
Athena. - The log format is explained here: Log Format
- Do NOT set your logging bucket to be the monitored bucket. It will create a infinite logging loop, and your bucket will grow in size exponentially.
- For the S3 logging service to write logs to your destination bucket, you must grant it
s3:PutObjectpermission. You can do this using either aBucket Policy(recommended) or anAccess Control List(ACL)Bucket Policy(Recommended): This policy allows the S3 logging service principal (logging.s3.amazonaws.com) to write objects into your specified log bucket and prefix.{ "Version": "2012-10-17", "Statement": [ { "Sid": "S3ServerAccessLogsPolicy", "Effect": "Allow", "Principal": { "Service": "logging.s3.amazonaws.com" }, "Action": "s3:PutObject", "Resource": "arn:aws:s3:::your-log-bucket-name/your-log-prefix/*", "Condition": { "ArnLike": { "aws:SourceArn": "arn:aws:ss3:::your-source-bucket-name" }, "StringEquals": { "aws:SourceAccount": "your-aws-account-id" } } } ] }Bucket ACL(Legacy): You grantWRITEandREAD_ACPpermissions on the target bucket to the AWSLog Deliverygroup. You can do this via the AWS Management Console or the AWS CLI.aws s3api put-bucket-acl \ --bucket your-log-bucket-name \ --grant-write 'uri=http://acs.amazonaws.com/groups/s3/LogDelivery' \ --grant-read-acp 'uri=http://acs.amazonaws.com/groups/s3/LogDelivery'
logging.s3.amazonaws.com) and an older, laminated ID card (Log Delivery group). Both cards belong to the same employee (the S3 Logging Service) and both grant access to the same building (your destination bucket). They just work with different security systems (IAM vs. ACLs).Once permissions are set on the target bucket, you enable logging on the source bucket. Create a
logging.jsonfile and then apply the configuration to your source bucket.{ "LoggingEnabled": { "TargetBucket": "your-log-bucket-name", "TargetPrefix": "your-log-prefix/" } }aws s3api put-bucket-logging \ --bucket your-source-bucket-name \ --bucket-logging-status file://logging.json
📉Performance
Amazon
S3automatically scales to high request rates, latency 100-200 msYour application can achieve at least 3,500
PUT/COPY/POST/DELETEand 5,500GET/HEADrequests per second per prefix in a bucket.There are no limits to the number of prefixes in a bucket.
Example (object path => prefix):
- bucket/folder1/sub1/file => /folder1/sub1/
- bucket/folder1/sub2/file => /folder1/sub2/
- bucket/1/file => /1/
- bucket/2/file => /2/
If you spread reads across all four prefixes evenly, you can achieve (5500 * 4) = 22,000 requests per second for
GETandHEADS3 –
KMSLimitation - If you useSSE-KMS, you may be impacted by the KMS limits. When you upload, it calls theGenerateDataKeyKMS API. When you download, it calls theDecryptKMS API. These count towards the KMS quota per second (5500, 10000, 30000 req/s based on region). As of today, you cannot request a quota increase for KMS.Multi-Part upload: Recommended for files > 100MB, must use for files > 5GB. Can help parallelize uploads (speed up transfers)
S3 Transfer Acceleration (
S3TA) - Increase transfer speed by transferring file to an AWSEdge Location. From there it will forward the data to theS3bucket in the target region. Compatible with Multi-Part upload.S3 Byte-Range Fetches - Using the
RangeHTTP header in aGETObject request, you can fetch a byte-range from an object, transferring only the specified portion. ParallelizeGETsby requesting specific byte ranges. Better resilience in case of failures. Can be used to speed up downloads. Can be used to retrieve only partial data (for example theHEADof a file)S3 Select&Glacier Select- Retrieve less data using SQL by performing server side filtering. Can filter by rows & columns (simple SQL statements). Less network transfer, less CPU cost client-side
⏲Transfer Acceleration
AWS S3 Transfer Acceleration (S3TA) is a bucket-level feature that speeds up data transfers to and from your S3 bucket by using AWS’s globally distributed CloudFront Edge Locations. This bypasses the public internet for the majority of the journey, reducing latency and increasing throughput.
S3TAroutes data through the AWS global network, which is optimized for performance. When you upload data, it goes to the nearest Edge Location and then travels over the dedicated AWS backbone network to yourS3bucket.The
S3bucket name must be DNS-compliant and cannot contain periods (e.g., my-bucket-name is ✅, but my.bucket.name is ❌).Could be enabled via Console, CLI or SDKs:
aws s3api put-bucket-accelerate-configuration \ --bucket YOUR-BUCKET-NAME \ --accelerate-configuration Status=EnabledOnce enabled on the bucket you must change the endpoint you use for transfers:
- Normal S3 Endpoint:
https://<bucket-name>.s3.<region>.amazonaws.com - S3 Transfer Acceleration Endpoint:
https://<bucket-name>.s3-accelerate.amazonaws.com
aws s3 cp --endpoint-url https://<bucket-name>.s3-accelerate.amazonaws.com \ <file-path> s3://<bucket-name>/- Alternatively, you can configure the AWS CLI to use the accelerated endpoint by default:
aws configure set default.s3.use_accelerate_endpoint true- Normal S3 Endpoint:
ᝰ.ᐟPresigned URLs
We can give users access to files in a bucket without giving them access to the bucket itself using
Presigned URLs. We can generate pre-signed URLs using SDK or CLI- For downloads (easy, can use the CLI)
- For uploads (harder, must use the SDK)
Valid for a default of 3600 seconds, can change timeout with
--expires-inargumentUsers given a pre-signed URL inherit the permissions of the person who generated the URL for
GET/PUTExamples :
- Allow only logged-in users to download a premium video on your
S3bucket - Allow an ever changing list of users to download files by generating URLs dynamically
- Allow temporarily a user to upload a file to a precise location in our bucket
- Allow only logged-in users to download a premium video on your

🔊Events
- When some events happen in the
S3bucket (for e.g. S3:ObjectCreated, S3:ObjectRemoved, S3:ObjectRestore, S3:Replication…) you can create event notification rules and these rules would emit events which could trigger other AWS services likeSQS,SNS,Lambdafunctions andEventBridgelike so: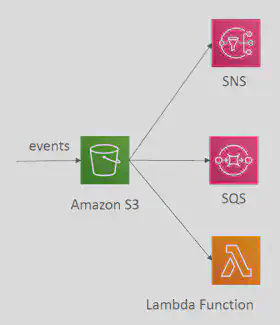
- Object name filtering possible (*.jpg)
- S3 event notifications typically deliver events in seconds but can sometimes take a minute or longer
- If two writes are made to a single non-versioned object at the same time, it is possible that only a single event notification will be sent
- If you want to ensure that an event notification is sent for every successful write, you have to enable versioning on your bucket.
🔌S3 - VPC Endpoints
A VPC endpoint is a virtual scalable networking component you create in a VPC and use as a private entry point to supported AWS services and third-party applications. Currently, two types of VPC endpoints can be used to connect to Amazon S3: Interface VPC endpoint and Gateway VPC endpoint. In both scenarios, the communications between the service consumer and the service provider never gets out of the AWS network.
Read more: VPC Endpoints
When you create a S3
VPC endpoint, you can attach an endpointResource-Basedpolicy to it that controls access to AmazonS3.Here is a sample
VPCendpoint policy to allow access to a specificS3bucket from within aVPC:{ "Statement": [ { "Sid": "Access-to-specific-bucket-only", "Principal": "*", "Action": [ "s3:GetObject", "s3:PutObject" ], "Effect": "Allow", "Resource": ["arn:aws:s3:::my_secure_bucket", "arn:aws:s3:::my_secure_bucket/*"] } ] }- While this is useful, as the number of buckets owned by the organization grows, it becomes difficult to keep track and manually specify newly created buckets in the Amazon
S3VPC endpoint policy. For example, when a new S3 bucket is created in a particular account that the application running within a VPC needs access to, you have to manually edit the VPC endpoint policy to allow list the newly createdS3bucket.
- While this is useful, as the number of buckets owned by the organization grows, it becomes difficult to keep track and manually specify newly created buckets in the Amazon
To make this simpler to manage, we look at Amazon S3 Access Points.
🛂S3 – Access Points
S3 Access Points are unique hostnames that you can create to enforce distinct permissions and network controls for any request made through the Access Point.
Some key features of S3 Access Points:
Access Points contain a
hostname, an AWSARN, and an AWS IAMResource-Basedpolicy.Access Points by default have a specific setting to
Block Public Access.Access Points are unique to an
AccountandRegion.Access Points can have custom
IAMpermissions for a user or application.Access Points can have custom
IAMpermissions to specific objects in a bucket via aprefixto precisely control access.Access Points can be configured to accept requests only from a virtual private cloud (
VPC) to restrict Amazon S3 data access to a private network.The following image shows one example of how you can use S3 Access Points to manage access to shared datasets on Amazon S3.

The scenario involves securing an
S3bucket to allow specific groups - Developers, Testers, and DevOps access to their designatedprefixeswhile restricting everyone else. Furthermore, all access to the bucket must be funneled through aVPC Endpoint, ensuring no direct public internet access is possible.- Developers need read/write access to the
/developprefix. - Testers need read/write access to the
/testprefix. - DevOps needs read/write access to both the
/developand/testprefixes.
- Developers need read/write access to the
All access to the
S3bucket is restricted to a specificVPC. This is achieved by creating aVPC EndpointforS3and configuring the bucket policy to deny all requests not originating from that endpoint.A single S3
Access Pointis used to manage all group permissions, simplifying policy management.Here is the
Resource-Basedpolicy for the S3Access Point:{ "Version": "2012-10-17", "Statement": [ { "Sid": "AllowDevelopersToDevelopersPrefix", "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::123456789012:role/DeveloperRole" }, "Action": [ "s3:GetObject", "s3:PutObject", "s3:ListBucket" ], "Resource": "arn:aws:s3:us-east-1:123456789012:accesspoint/my-access-point/object/developers/*" }, { "Sid": "AllowTestersToTestPrefix", "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::123456789012:role/TesterRole" }, "Action": [ "s3:GetObject", "s3:PutObject", "s3:ListBucket" ], "Resource": "arn:aws:s3:us-east-1:123456789012:accesspoint/my-access-point/object/test/*" }, { "Sid": "AllowDevOpsToBothPrefixes", "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::123456789012:role/DevOpsRole" }, "Action": [ "s3:GetObject", "s3:PutObject", "s3:ListBucket" ], "Resource": [ "arn:aws:s3:us-east-1:123456789012:accesspoint/my-access-point/object/developers/*", "arn:aws:s3:us-east-1:123456789012:accesspoint/my-access-point/object/test/*" ] }, { "Sid": "DenyEveryoneElse", "Effect": "Deny", "Principal": "*", "Action": [ "s3:GetObject", "s3:PutObject", "s3:DeleteObject" ], "Resource": [ "arn:aws:s3:us-east-1:123456789012:accesspoint/my-access-point/object/developers/*", "arn:aws:s3:us-east-1:123456789012:accesspoint/my-access-point/object/test/*" ], "Condition": { "StringNotEquals": { "aws:PrincipalArn": [ "arn:aws:iam::123456789012:role/DeveloperRole", "arn:aws:iam::123456789012:role/TesterRole", "arn:aws:iam::123456789012:role/DevOpsRole" ] } } } ] }
S3 - Multi-Region Access Points
- Provide a
global endpointthat spanS3buckets in multiple AWS regions - Dynamically route requests to the nearest
S3bucket (lowest latency) - Bi-directional
S3bucket replication rules are created to keep data in sync across regions - Failover Controls – allows you to shift requests across S3 buckets in different AWS regions within minutes (Active-Active or Active-Passive)

(λ) S3 - Object Lambda
If you want to provide different customized views of S3 objects (e.g., redacted, filtered, enahanced) to multiple applications, there are currently two options:
- You either create, store, and maintain additional derivative copies of the data
- You build and manage infrastructure as a proxy layer in front of S3 (
APIGateWay+Lambda) to intercept and process data as it is requested.
Both options add complexity and costs.
S3 Object Lambdasolves this problem. It intercepts standard S3GETrequests and routes them through aLambdafunction that transforms the object before returning it. The client still thinks it’s callingS3.- It works natively with S3
Access Points,IAMpolicies, and bucket permissions.

There are many use cases that can be simplified by this approach, for example:
- Redacting PII for analytics or non-production environments.
- Converting across data formats, such as converting
XMLtoJSON. - Augmenting data with information from other services or databases.
- Compressing or decompressing files as they are being downloaded.
- Resizing and watermarking images on the fly using caller-specific details, such as the user who requested the object.
- Implementing custom authorization rules to access data.
🔐S3 - Object Lock
- S3
Object Lockenables write-once-read-many (WORM) protection for objects in Amazon S3. - It prevents deletion or modification for a specified retention period or indefinitely (via legal hold).
- This is crucial for compliance use cases.
- Glacier
Vault Lockapplies a similarWORMmodel at the vault level in AmazonS3 Glacier. - Once a Vault Lock policy is set and locked, it enforces compliance controls—such as denying deletion requests—across all archives in the vault.
- This is ideal for long-term archival with regulatory retention requirements.
✨Best Practices
- Use random hash prefix for keys and ensure a random access pattern, as
S3stores object lexicographically (meaning keys are sorted alphabetically) randomness helps distribute the contents across multiple partitions for better performance.- If many keys share a common prefix (e.g.
logs/2025-09-26/), S3 routes them to the same partition, creating a hot partition. This can throttle throughput and degrade performance. - Prepend a randomized hash prefix (e.g.,
a9f3-logs/2025-09-26/) to each key. This distributes keys across multiple partitions improving parallelism forPUT,GET, andLISToperations - Avoids throttling due to partition hotspots
- If many keys share a common prefix (e.g.
- Use parallel threads and Multipart upload for faster writes
- Use parallel threads and Range Header GET for faster reads
- For list operations with large number of objects, its better to build a secondary index in
DynamoDB - Use Versioning to protect from unintended overwrites and deletions, but this does not protect against bucket deletion
- Use VPC S3 Endpoints with VPC to transfer data using Amazon internal network